 Diagnostic Manual
Diagnostic Manual
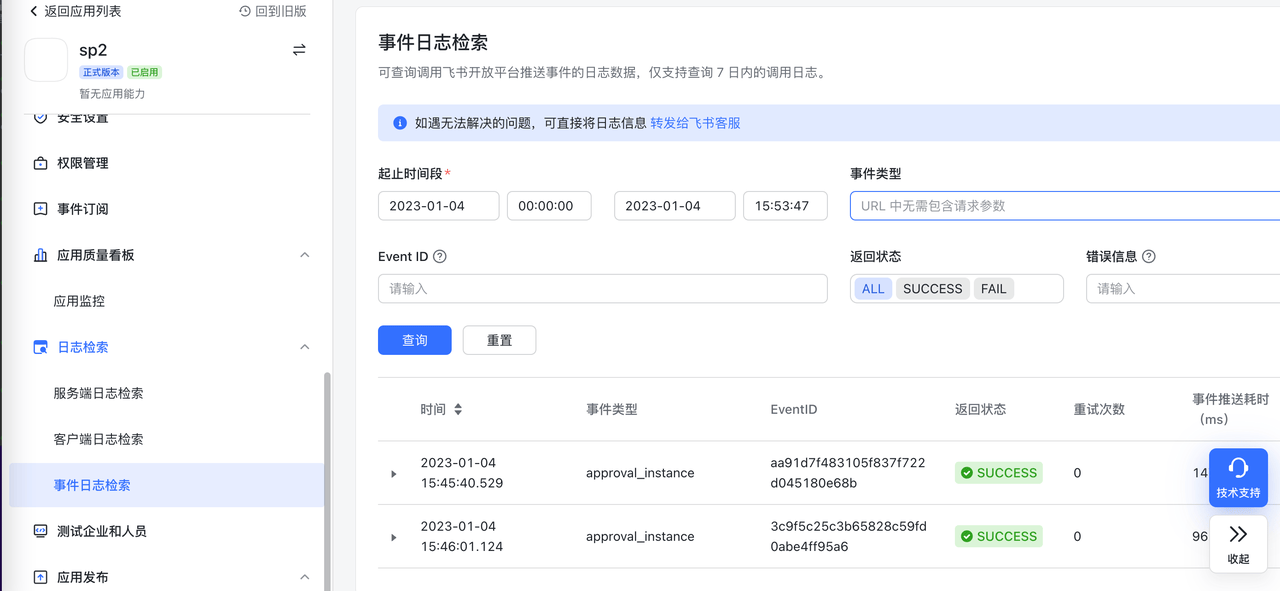
# If approval is still pending in Zadig after approval/rejection, check event logs to see if Feishu app event push requests are properly received
If approval is still pending in Zadig after approval/rejection, check event logs to see if Feishu app event push requests are properly received
# Go mod builds use proxy, but get "Too many connections" error when pulling packages. How to resolve?
This is caused by too many connections to the proxy server. You can ask operations staff for assistance or optimize proxy server configuration by using transparent proxy to reduce connection count.
# Frontend builds locally work fine, but online builds fail with package.json errors, unable to pull dependencies. How to resolve?
Follow this troubleshooting process step by step:
- Check if package.json has private dependencies, and if so, confirm you have read permissions
- Verify build scripts are the same as local
- Check if versions used in build match local build versions to rule out version issues
# Workflow task build time is too long or stuck. How to resolve?
Scenarios and corresponding solutions:
- Code repository uses submodule but code can't be pulled, git submodule update hangs: Recommend using Proxy in system settings, see: Proxy Configuration
- Frequently unable to pull GitHub code: Recommend using Proxy in system settings
- Code build has external dependencies that can't be pulled: Recommend using Proxy in build scripts or configuring domestic sources as alternatives
- Workflow task gets stuck after triggering, no output in real-time build logs: Troubleshoot with following steps
# 1. Query Pods with abnormal status
kubectl get pod -n <namespace>
# 2. View detailed information of abnormal Pods
kubectl describe pod <podName> -n <namespace>
2
3
4
5
# Diagnosing issues with packages unable to upload to object storage in builds
Follow this troubleshooting process step by step:
- Check if this build selected the wrong branch or pull request
- Check if upload-related business tool parameters in build script are configured correctly
- Confirm third-party storage service is continuously available
- Ask operations staff to help confirm if nodes in current cluster have network resolution issues
# Diagnosing image push failures
You can troubleshoot following this process:
- Confirm the image registry being used has network connectivity and is functional
- Confirm if the image registry has set a default maximum image count limit, as image count may have reached the limit
# Workflow - Build Error Diagnosis
# no cotainer statuses : s-task=pipelineName-548,s-service=serviceName,s-type=buildv2,p-type=workflow
You can check the specific Job status and logs with the following operations:
kubectl get pod -n <namespace> |grep <pipelineName>
# After finding the corresponding Pod, you can check the specific Pod logs
kubectl logs -f <pod/podName> -n <namespace>
2
3
# no space left on device
This is caused by insufficient space in the PVC mounted by Zadig system's spock-dind service. You can use our system settings - system configuration - cache cleanup feature to clean this data with one click. See Cache Cleanup
# Failed parsing or buffering the chunk-encoded client body
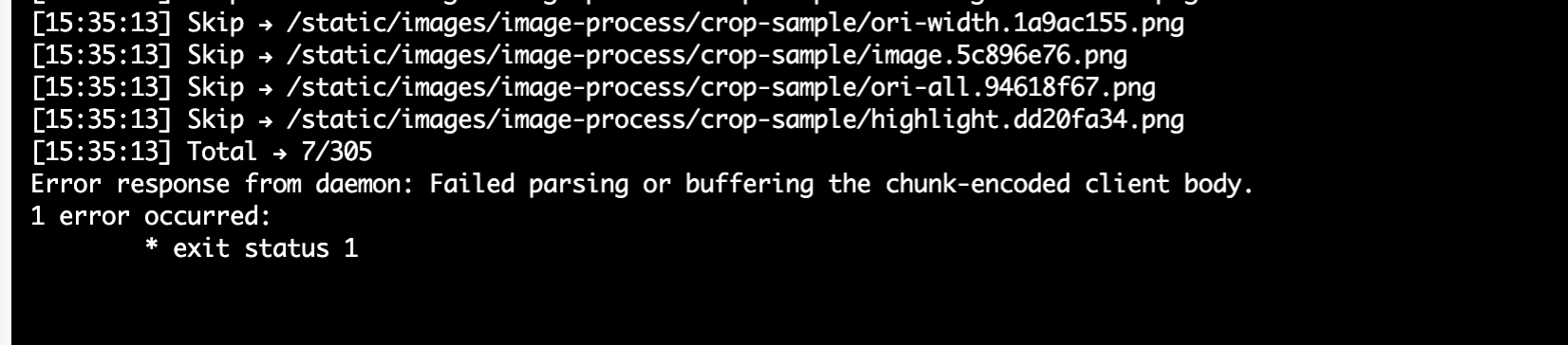
When the above error occurs during build tasks, you need to confirm if a proxy was used before docker build. If a proxy is set, docker build will go through the proxy causing failure. Solution: Add the following command before docker build
unset http_proxy https_proxy
# 500:Internal Error:-148643:action not allow status code:403 ...
When the above error occurs during build tasks, you need to confirm if the integrated default object storage has enabled upload, download, delete files, and list files permissions.
# Error response from daemon: Get https://*****: x509: certificate signed by unknown authority
When the above error occurs during build tasks, this is because a self-signed certificate is used when logging into a private image registry. This certificate is not issued by a trusted certificate authority (CA), so the Docker daemon doesn't trust the certificate and reports an x509 self-signed certificate error. You can refer to Image Registry Configuration to disable SSL verification.
# COPY failed: stat /var/lib/docker/tmp/docker-builder124714399/workspace/demo/exec.sh: no such file or directory
When the above error occurs while executing a COPY command in Dockerfile, please check the relationship between Docker build context and the copied file path. The build will only succeed when the copied file can be found using a relative path in the build context directory. Example:
Dockerfile content:
From ubuntu:18.04
WORKDIR /root/zadig
COPY ./demo/exec.sh /root/zadig/exec.sh
COPY /absolute/path/to/zadig/demo/exec.sh /root/zadig/exec.sh
2
3
4
Docker build command:
cd /absolute/path/to/zadig
docker build -t demo:latest -f Dockerfile . # Build context is current directory (i.e. /absolute/path/to/zadig)
2
Conclusion:
COPY ./demo/exec.sh /root/zadig/exec.shwill succeed.COPY /absolute/path/to/zadig/demo/exec.sh /root/zadig/exec.shwill fail.
For more information, see Docker build | Extended description(opens new window)
# Webhook Trigger Configuration Failure
# POST http://gitlab....com/api/v4/projects/owner+repo/hooks: 422 {error: Invalid url given}
When using GitLab 14.0+ to configure Webhook triggers in workflows and getting the following error:
400 : Failed to create or update workflow 1 error occurred: * POST http://gitlab....com/api/v4/projects/owner+repo/hooks: 422 {error: Invalid url given}
This is a GitLab configuration issue. Use the following configuration to resolve. See: allow_local_requests_from_hooks_and_services(opens new window)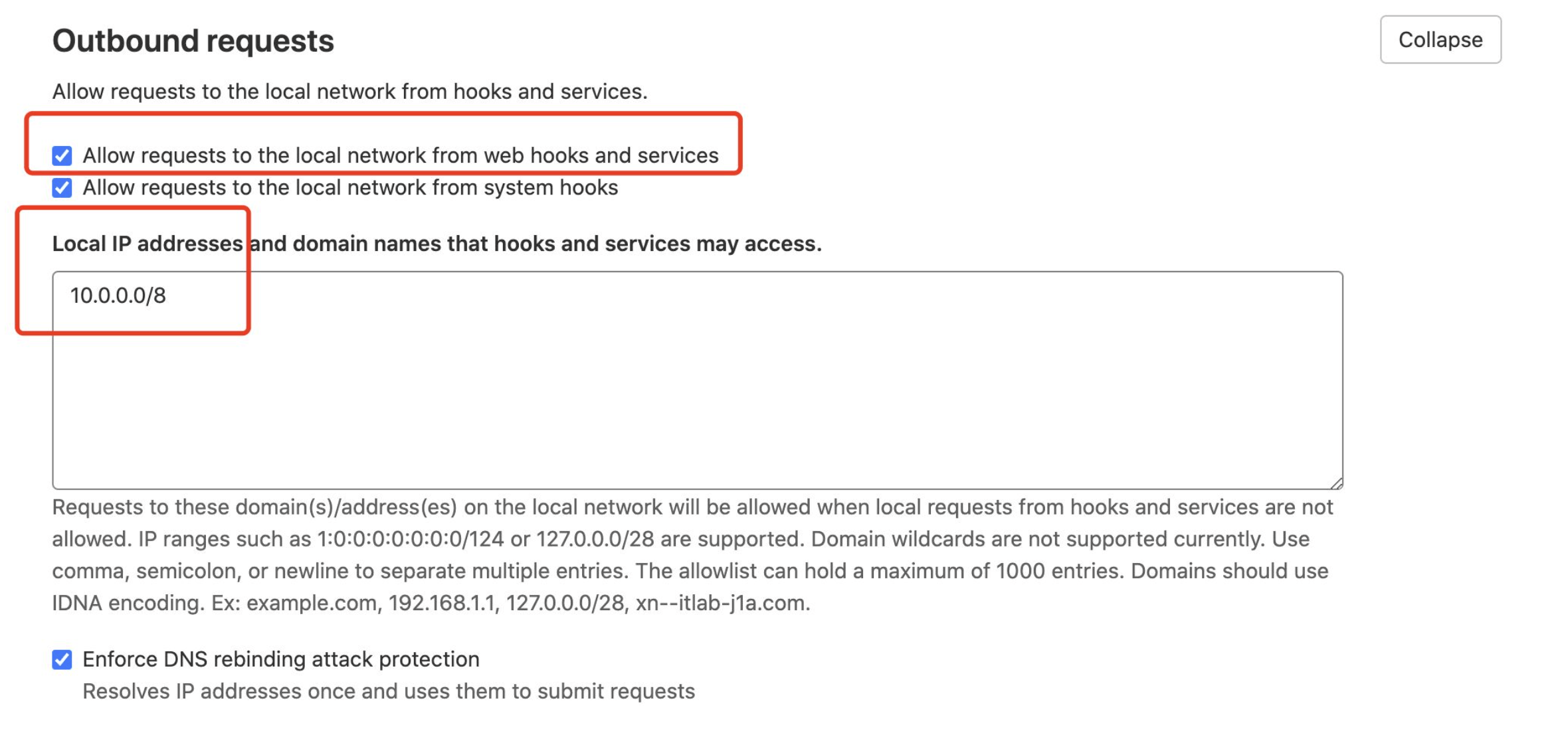
# Hook executed successfully but returned HTTP 404 Invalid path: /api/gitlabhook
When manually adding Webhook in GitLab, the following error occurs:
Hook executed successfully but returned HTTP 404 Invalid path: /api/gitlabhook
After configuring triggers in workflows, there's no need to manually add Webhook settings in GitLab system.
# When syncing service configuration from code repository to create K8s YAML services, service configuration in Zadig platform doesn't sync after changes in code repository. How to troubleshoot?
- Check service configuration to ensure the code source, owner, repository, branch, and file path for configuration changes in the code repository match those in Zadig platform.
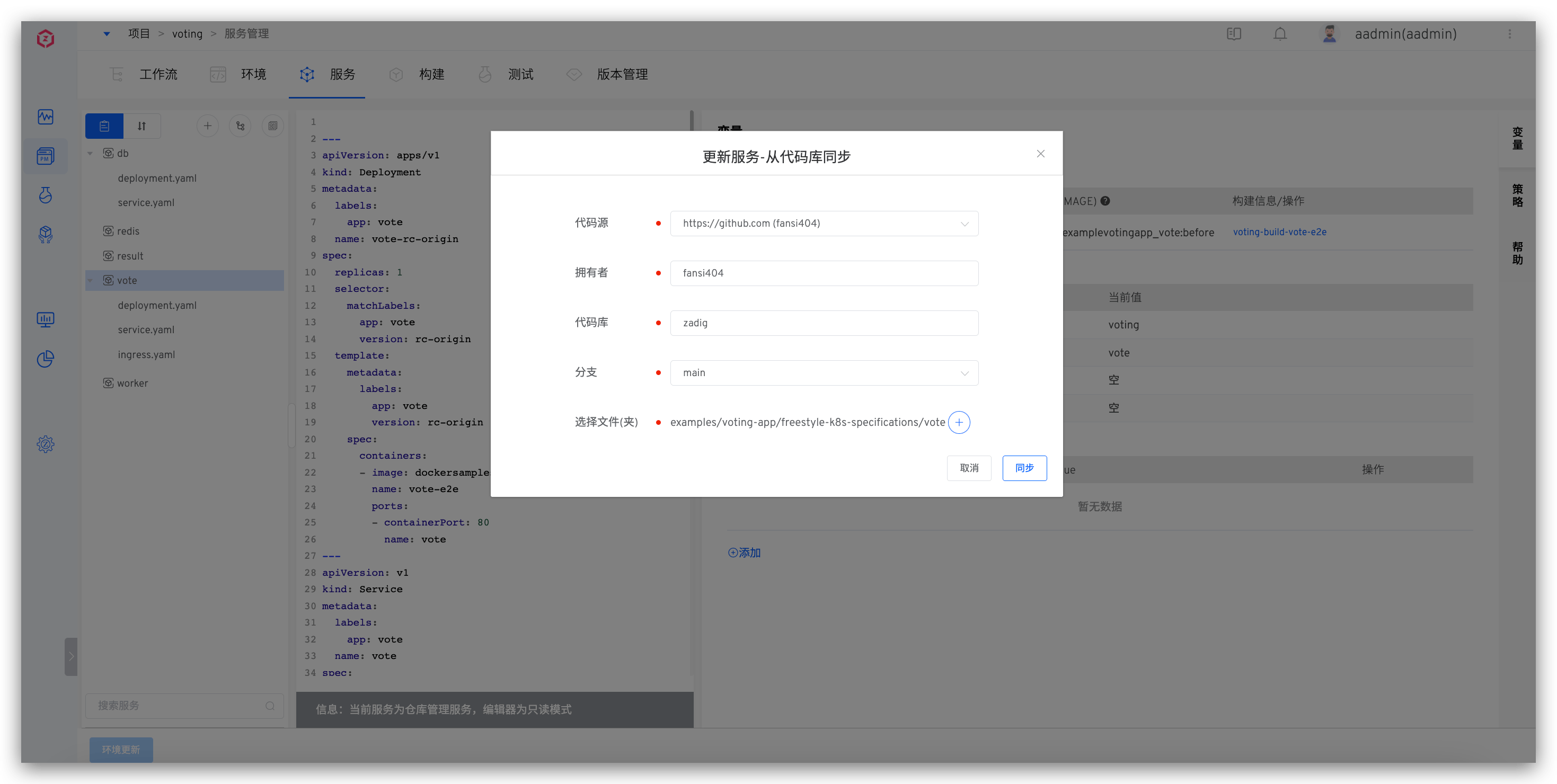
Ensure content after service configuration changes in code repository is valid YAML content.
Use the following command to view aslan service logs, locate the
SyncServiceTemplatekeyword, and analyze its contextual information.
kubectl -n <Zadig Namespace> | grep aslan # Get aslan Pod name
kubectl -n <Zadig Namespace> logs <aslan Pod name> -c aslan
2
# Workflow Webhook trigger configured but not working, what troubleshooting approaches are available?
When configuring Webhook triggers in workflows without obvious errors, but triggers don't work when code changes occur. Here are several common troubleshooting approaches.
# Check Webhook Configuration in Zadig Platform
Edit the specific workflow, switch to the Triggers tab to view Webhook configuration details, and ensure code changes and Webhook events meet trigger conditions. For parameter descriptions in configuration, see Webhook Configuration.
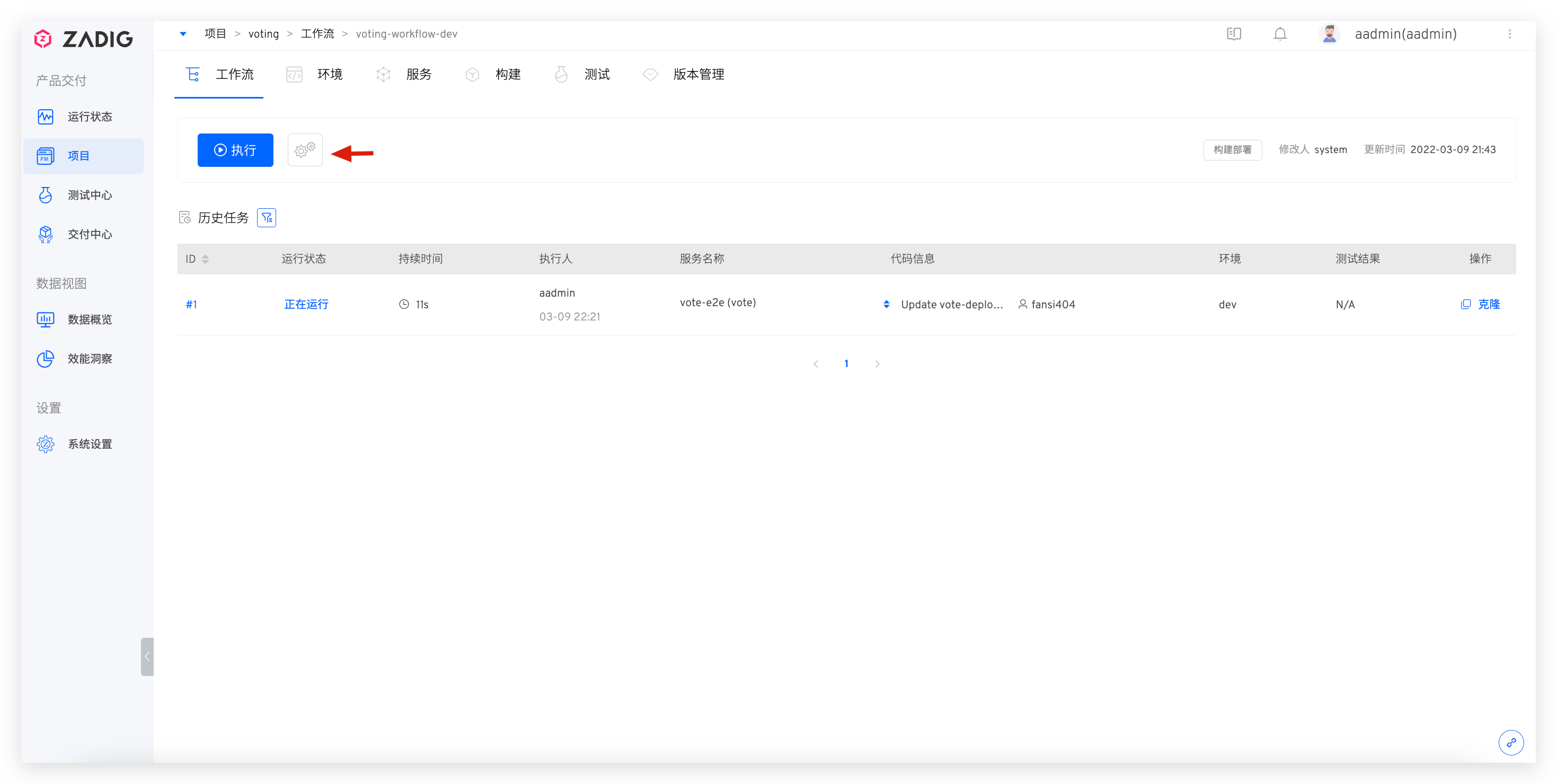
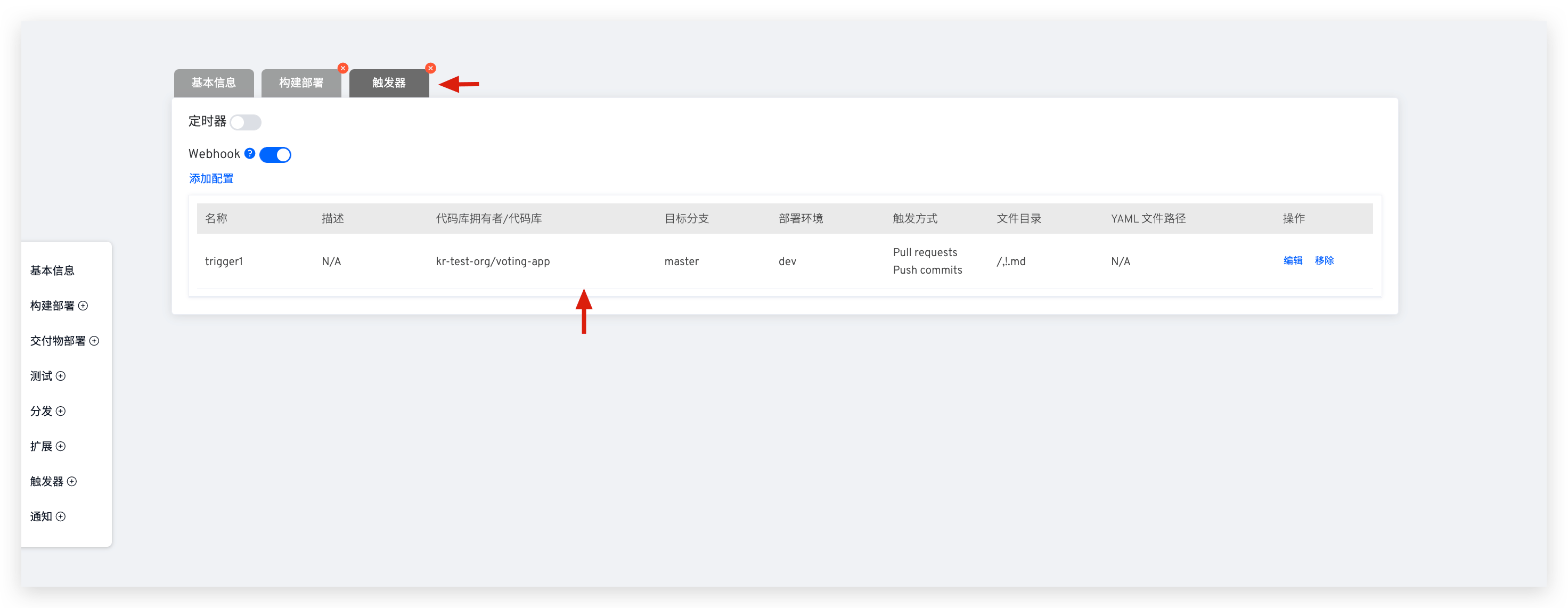
# Check Webhook Configuration in GitHub Repository
- Visit the specific GitHub repository -
Settings-Webhooksto view current project's Webhook configuration list.
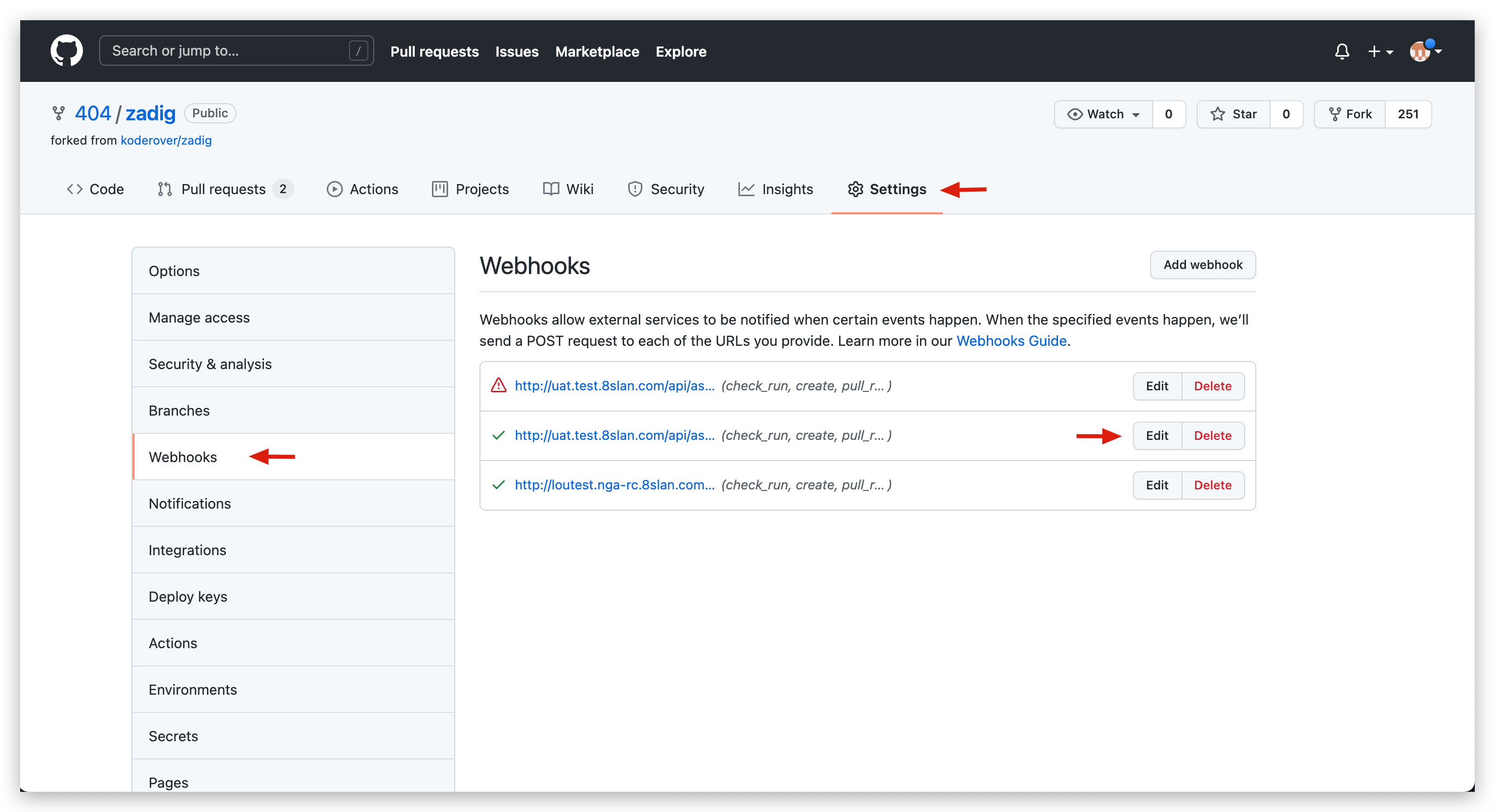
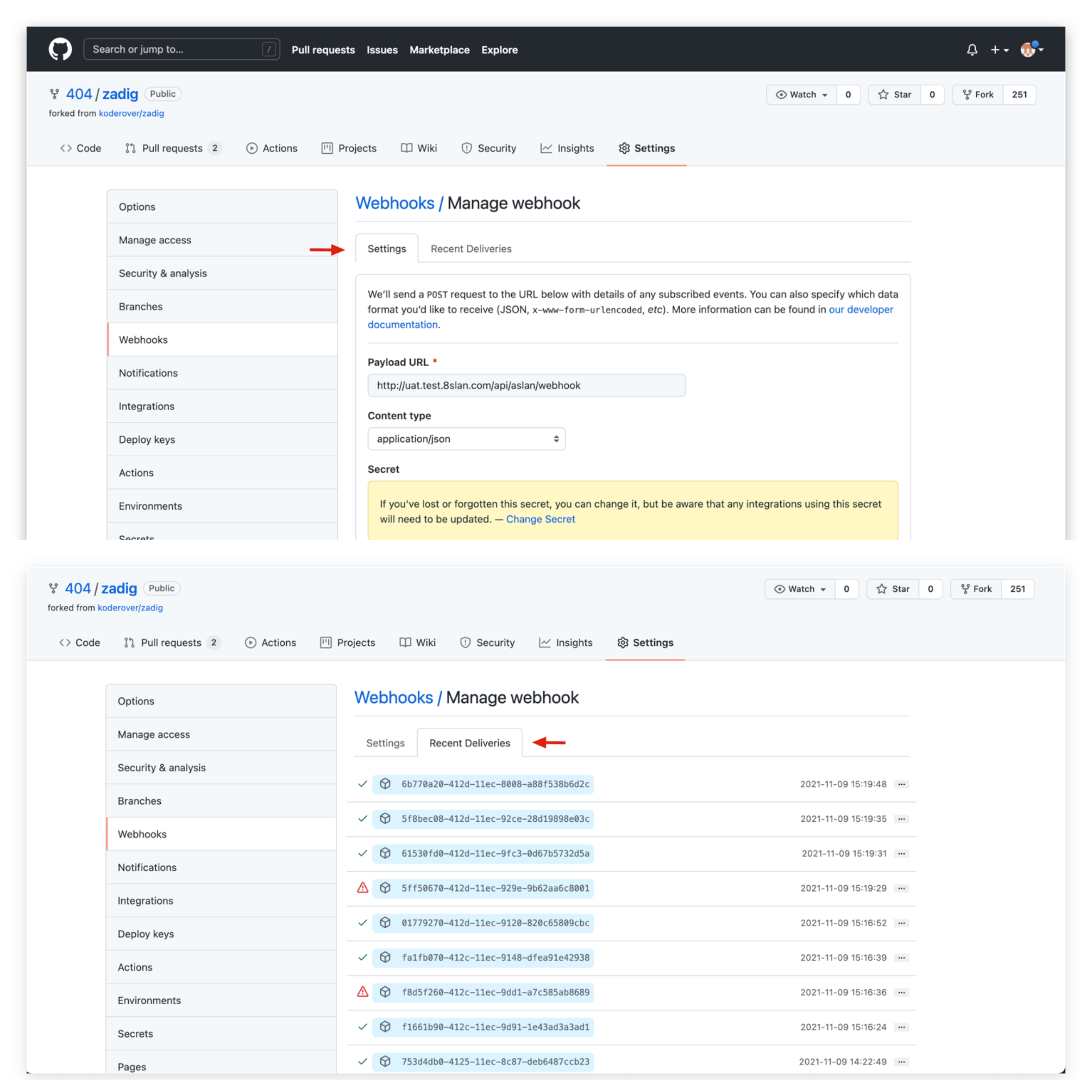
- In
Settings, view specific Webhook configuration, and check recent Webhook Events and status inRecent Deliveries.
# Check Webhook Configuration in GitLab Repository
- Visit the specific GitLab repository -
Settings-Webhooksto view current project's Webhook configuration list.
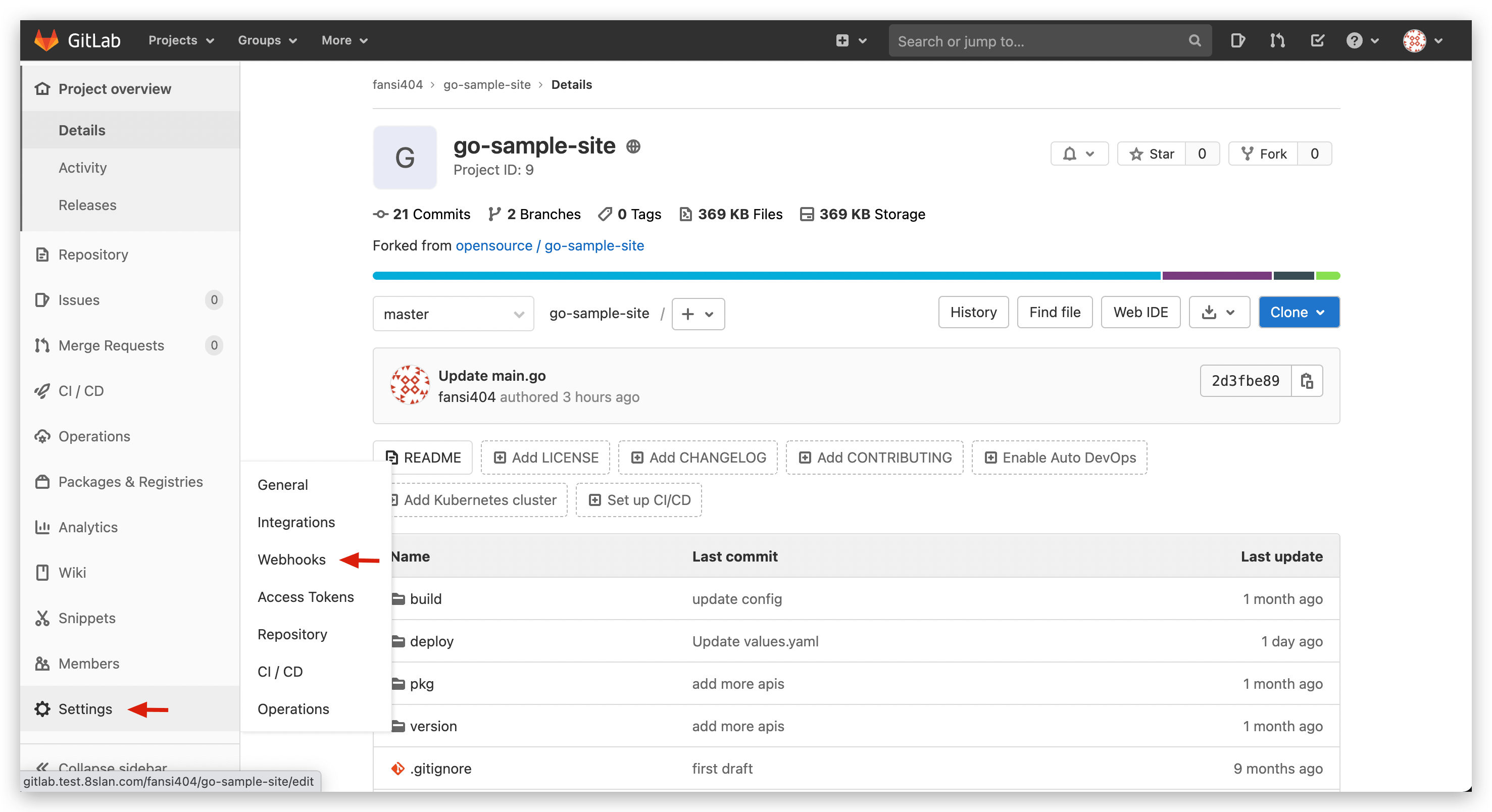
Testoperation can test Webhook settings, clickEditto view recent Webhook Events and status.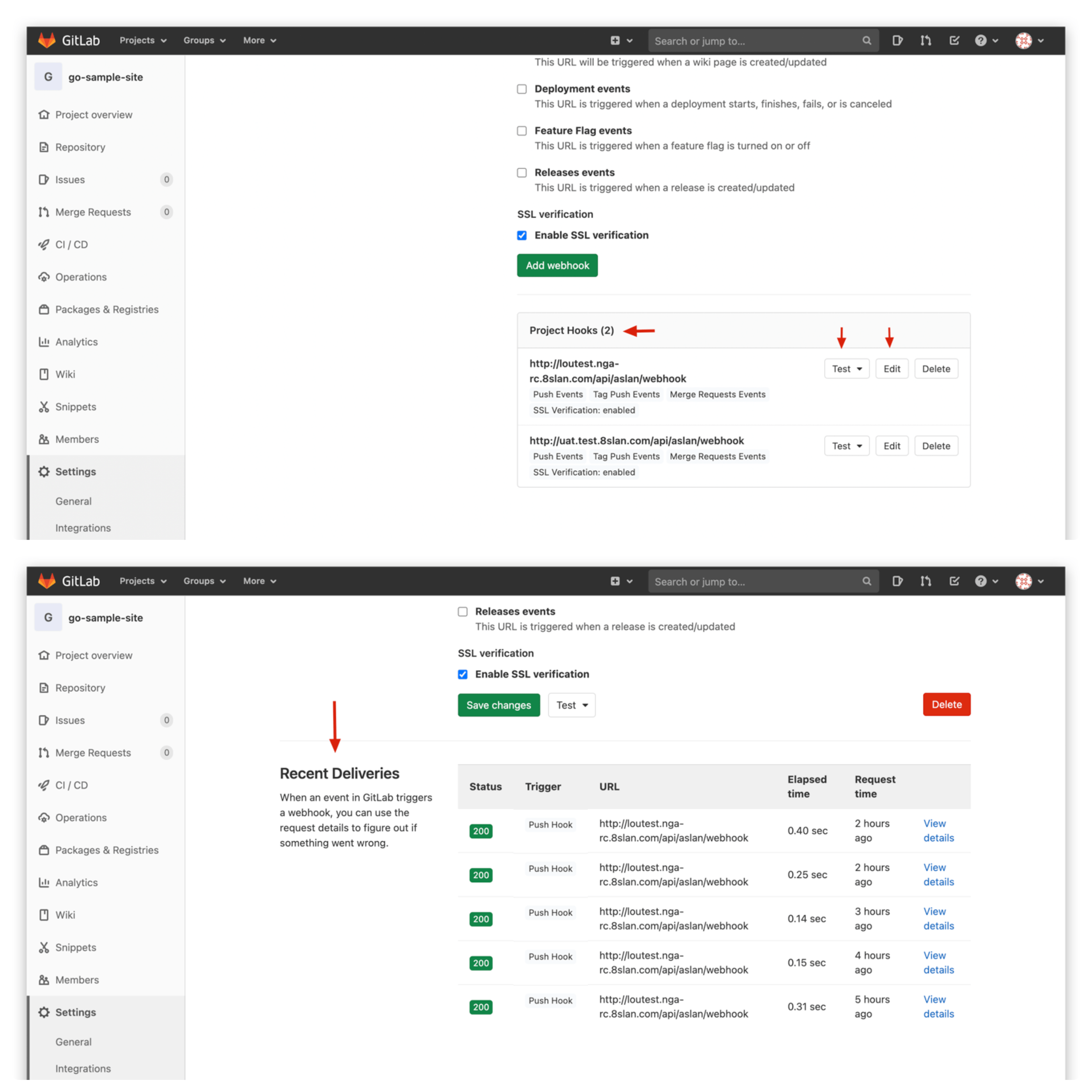
# View aslan Service Logs
- Submit new code change requests while using the following command to view real-time logs of aslan service, locate the
webhookkeyword, and analyze its contextual information.
kubectl -n <Zadig Namespace> | grep aslan # Get aslan Pod name
kubectl -n <Zadig Namespace> logs -f <aslan Pod name> -c aslan
2
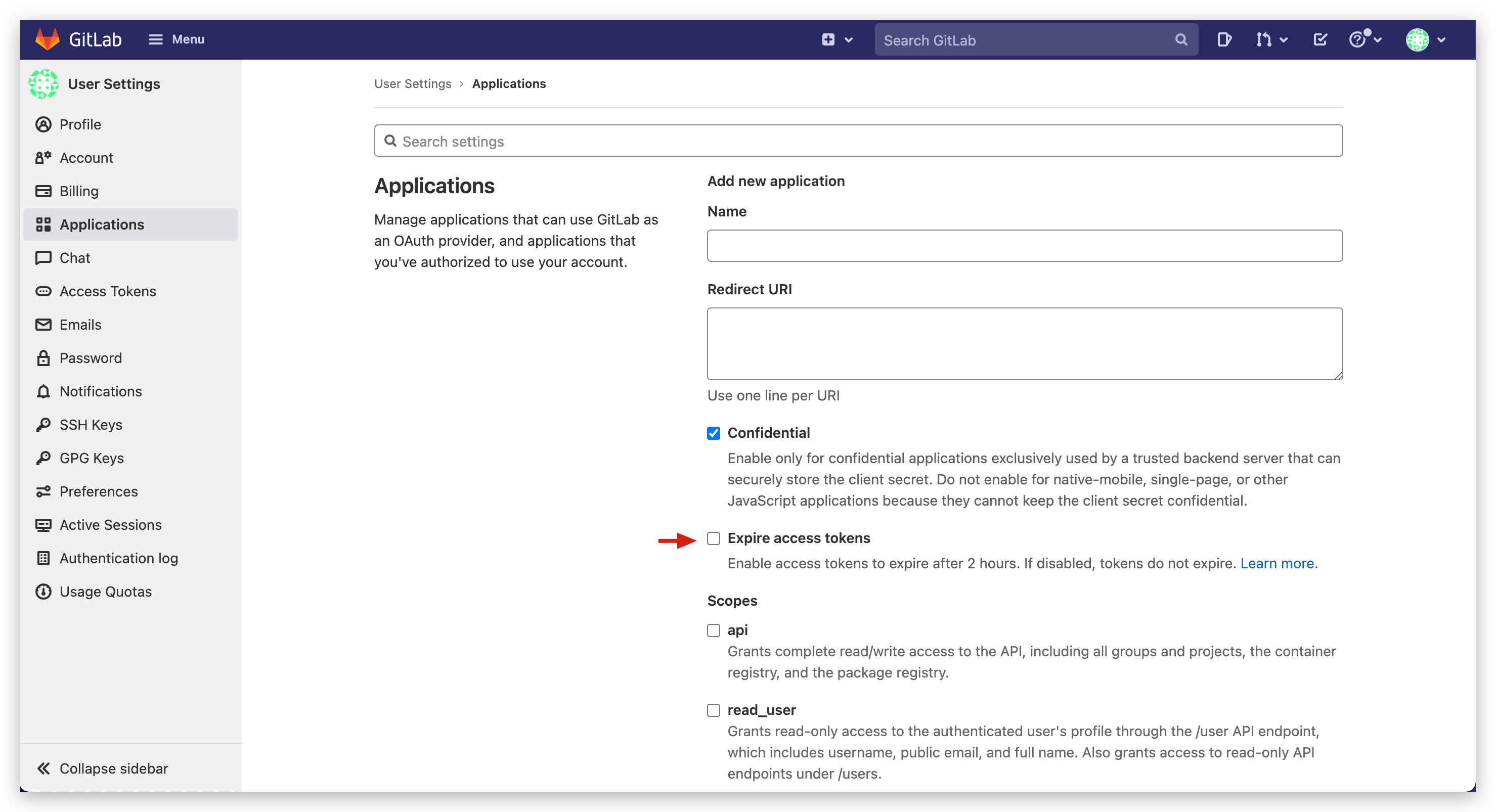
# After integrating GitLab repository, using it reports 401 Unauthorized, need to re-authorize GitLab code source in system settings before normal use
GitLab 14.3 and above introduced the Expire access tokens feature, where Application access tokens have a default validity of 2 hours. Visit GitLab system's User Settings - Applications and uncheck Expire access tokens.
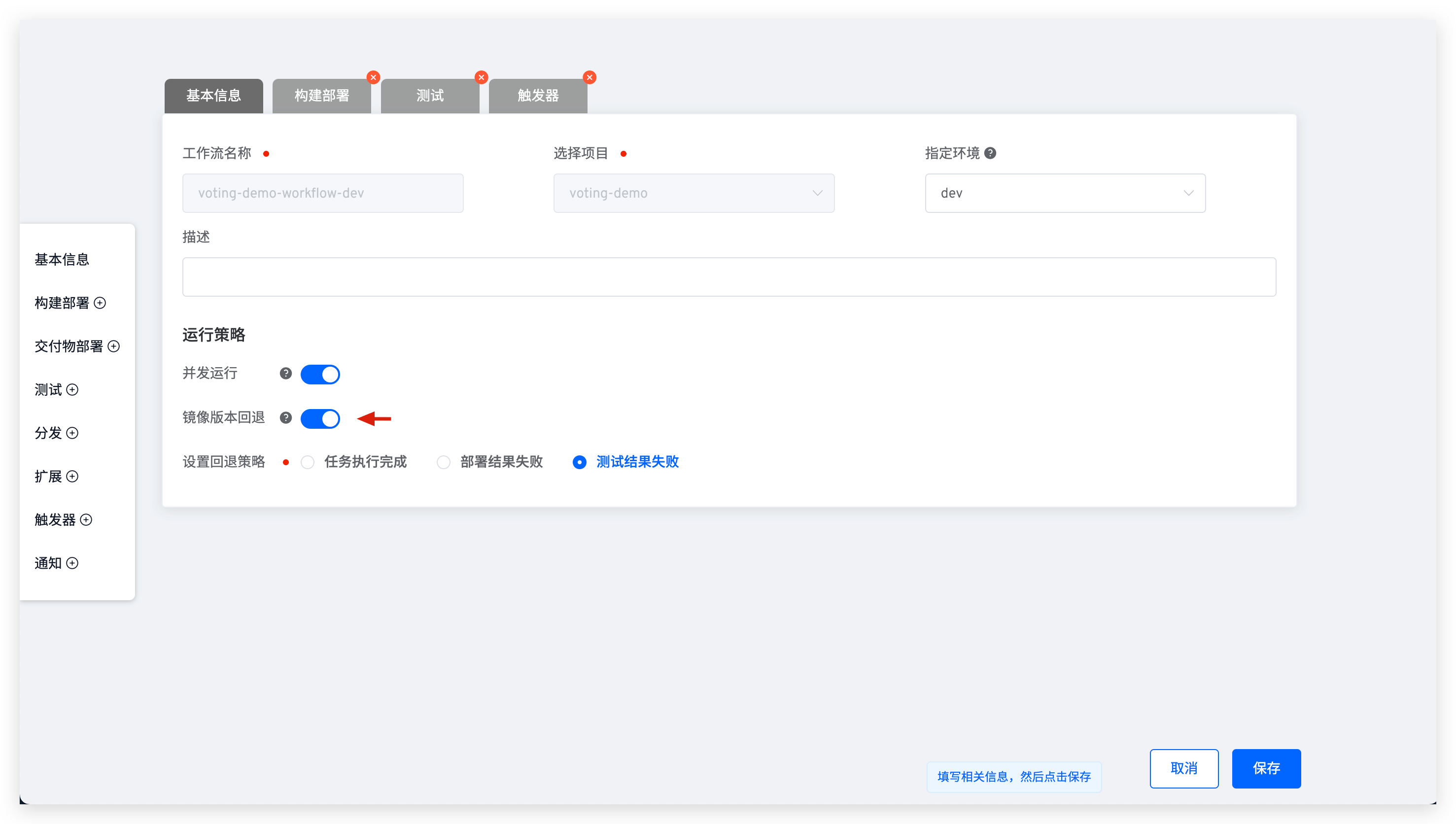
# After workflow task completes and deploys services, service image version is not updated. How to resolve?
Edit the workflow to check its configuration and see if the Image Version Rollback switch is enabled.
For more information, see Workflow Image Version Rollback
# Helm project workflow deployment encounters cannot re-use a name that is still in use or another operation (install/upgrade/rollback) is in progress error. How to resolve?
Helm release may be in an incorrect state due to some abnormal conditions. Use helm list -n <Namespace> -a -f <ReleaseName> and helm history <ReleaseName> -n <Namespace> commands to confirm release status and version records, and resolve according to the following situations:
- If release has a deployed version, manually rollback the release to the most recent deployed version. See: Helm Rollback(opens new window).
- If release is currently in superseded state and has no deployed version, manually execute helm upgrade command to upgrade release to new version. See: Helm Upgrade(opens new window).
- If release is in
pending-install/pending-upgrade/pending-rollbackstate for a long time and has no deployed version, manually delete the secret corresponding to the current release version from the cluster namespace. Secret name:sh.helm.release.v1.<ReleaseName>.v<ReleaseRevision>.
